
Large Language Models Concepts
Published:
[TOC]
Chapter 1 : Introduction to Large Language Models (LLM)
The rise of LLMs in AI landscape
AI has performed well in data-driven tasks such as sentiment analysis, fraud detection and more. However, it traditionally lacked ability to understand context, respond to open-ended questions, and generate human-like responses in conversation. Recent developments in language-based AI models have led to a disruptive breakthrough. These models, called Large Language Models, can process language as humans do.
LLMs use deep learning techniques to perform a variety of NLP (Natural Language Processing (NLP) is the technology that allows computers to understand, interpret, and generate human language in a meaningful way. This technology is often employed in applications such as translation services and chatbots.) tasks such as text classification, summarization, generation and more.
Definitions of LLMs :
Large : training data and resources Language : they are powerful in processing and analyze human language data Models : Learn complex patterns using text data
The defining moment :
The LLM is considered the defining moment. GPT series is one of the most popular language models among the family of LLMs, primarily because of its ability to engage in rich human interactions.
Applications :
Sentiment analysis, Identifying themes, Translating speech or text, Generating codes, Next-word prediction.
Objectives of this course
- Conceptual understanding of LLMs
- Training data considerations
- Ethical, privacy and environmental concerns
- wrap up this course by covering the enhancements and future work of LLMs
Real-world applications :
This section aims to understand business opportunities and benefits of leveraging LLMs.
Business opportunies
Benefits : Automate tasks, Improve efficiency, create revenue streams, enable new capacities. (自动化任务、提高效率、创造收入流、启用新能力。)
Transforming finance industry
Financial analysis of a company can be complex and may include processing unstructured text such as investement outlooks, annual reports, new articles, and socia media posts.
Unstructured data or text : data that lacks definition and is presented free-form. LLM can analyze such data to generate valuable insights into market trends, manage investments, and identify new investment opportunities.
Challenges in healthcare
Analyzing health records is important for giving personalized recommendations to provide quality healthcare. But, much of thees information is in doctors’ notes, which can be hard to understand because they use jargon and abbrevations. Further more, domain specific-knowledge and varying writing styles among practitioners add to the the challenges of interpreting this critical information effectively. Processing such varied data and understanding complex acronyms makes it difficult to have a general system to describe any patient files.
Revolutionizing healthcare sector
- LLMs can analyze patient data to offer personalized recommendations : medical records, health check-out results, imaging reports, to provide personalized treatment recommendations.
- Patient data is private and personnal, so anyone use LLM must adhere to privacy laws.
Education
- Personnalized coaching and feedback
- Interactive learning experience
- AI-powered tutor can ask questions, recevie guidance, discuss ideas
- Moreover, the tutor can adapt its teaching style based on the learner’s conceptual understanding.
Multimodol applications of LLM
Visual question answering : process both image and text data to generate responses.
Challenges of language modeling
Challenges of language modeling
- Sequence matters : Modeling a language requires understanding the sequential nature of text, because placing even one word differently can change the meaning of the sentence completely.
- Context Modeling : language is highly contextual, meaning the same word can have different meanings depending on the context in which it is used. To accurately model language, language models must analyze and interpret the surrounding words, phrases, and sentences to identify the most likely meaning of a given word.
- Long-range dependency
Single-task learning
For example :
Task 1 model –> Question Answering
Task 2 model –> Text Summarization
Tasl 3 model –> Translation
Issues : Time and resource expensive, less flexible compared to modern LLMs.
Multi-task Learning
With the development of LLMs, multi-task learning has become possible. This involves training a model to perform multiple related tasks simultaneously of traing separate models for each task. 
Advantages :
- (versatile) improved performance on each individual task (using new and unseen data, but may come at the expense of accuracy and efficiency 以牺牲准确性和效率为代价)
- Might impact accuray and efficiency
- it can decrease the training data needed for each individual task by allowing the model to learn from shared data across the tasks. 它可以通过允许模型从跨任务的共享数据中学习来减少每个单独任务所需的训练数据。
Comparison between single task and multitask learning : 
Chapter 2 : Building Blocks of LLMs
Novelty of LLMs
- LLMs Use text data : unstrutured data (messy and inconsistent)
- Issue : Machines do not understand languages !
- Need for NLP : Text data –> NLP –> Numerical form –> Enable computers to identify the patterns and features of text data
- Unique capabilities of LLMs : abilities to detect linguisitic subtleties like irony, humor, intonation and intents !
How do LLMs understand ?
- Trained on vast amounts of data
- Largeness of LLMs : parameters
- Parameters represent the patterns and rules learnf from training data
- More parameters allow for capturing more complex patterns, resulting in sophisticated and accurate responses
Emergence of new capacities
These massive parameters also give rise to LLMs’ emergent capabilities
- Emergent abilities : unique to large-scale models like LLMs and not found in smaller ones.
Scale : it is defined by the volume of training data and the number of model parameters (As the scale increases, the model’s performance can dramatically improve beyond a certain threshold, resulting in a phase transition and a sudden emergence of new capabilities
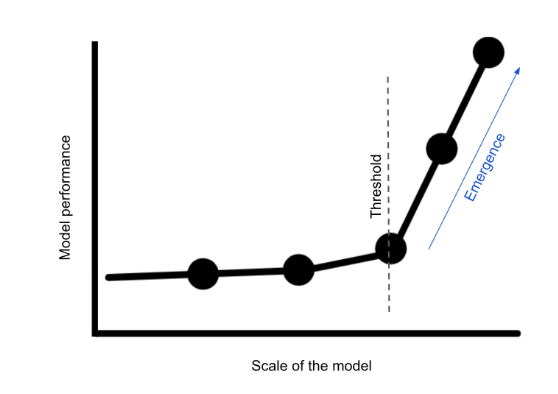
- Applications : Music, Poetry, Code generation, Medical diagnosis and treatment plans
Buidling blocks of LLMs
To reach this threshold, LLM and their parameters undergo a training process (Text pre-processing, text representation, pre-training, fine-tuning, advanced fine-tuning.)
To recap
- We learned how LLMs overcome data’s unstructured nature
- it outperform traditional models by comprehending complex linguistic subtleties and generating detailed responses
HOW? :
- this performance boost is a result of the “largeness” of LLMs, which is due to extensive training data and many parameters.
- These factors also enable “emergent abilities”, which unlock advanced capabilitie and expand LLMs’ use cases, making them a potent tool in Natural Language Processing.
Generalized overview of NLP
Key NLP techniques used to prepare text data into machine-readable form for use in LLMs
Text pre-processing
It transforms raw text data into a standardized format.
Steps : Tokenization, stop word removal and lemmatication
- Tokenization : splits text into individual words, or tokens. After tokenization, we obtain a list.
- Stop word removal : stop words do not add meaning (like “as”, “with” ,”is”, etc)
- Lemmatization : group slightly different words with similar meaning. It reduces words to their base form (talking–> talk, talked –> talk)
Text representation
It help convert preprocessed text into a numerical form (bag-of-words, word embeddings)
bag-of-words : it involves converting the text into a matrix of word counts (limitations : it fails to capture the order or context, can lead to incorrect interpretations; it does not capture the semantics between the words, beacuse it treats related words as independent)
Word embeddings : capture the semantic meanings as numbers, allowing for similar words to have similar representations.
for example : features are “plant, furry, carnivore”
- cat : [-0.9, 0.9, 0.9]
- mouse : [-0.8, 0.7, -0.8]
so cat is furry and carnivore; mouse is furry.
Machine-readable form
Convert pre-processed text to numerical format : text data –> tokenization stop-word removal lemmatization –> bag of words / word embedding –> Numerical data
Fine-tuning
Fine-tuning is an effective approche used to help LLMs overcome certain challenges Building these models requires powerful computers and specialized infrastructure due to the massive amounts of data and computational resources involved
Computing power
- Memory
- Processing power
- infrastructure
- expensive
- LLM : 100,000 Central Processing Units (CPUs), 10,000 Graphic Processing Units (GPUs)
Efficient model training
Chanllenges : significant training time, may take weeks or even months
Efficient model training = faster training time
Data availiability
- Needs of high-quality data
- to learn the complexities and subtleties of language
- A few hundred gibagytes (GBs) of text data (more than a million books)
- massive amount of data
Learning techniques
Fine-tuning : training a pre-trained model for a specila task
But, what if there is little to no labeled data ?但是,如果标记数据很少甚至没有怎么办?
N-shot learning : zero-short, few-short, and multi-short (theses techniques are part of transfer learning)
Transfer learning :
Learn from one task and transfer to related task (like transfering knowledge from piano to guitar)
N-shot leaning :
- zero-shot - no task - specific data
- few-shot - little task - specific data
- multi-shot - relatively more training data
Zero-shot learning
- it allows LLMs to perform a task it has not been explicitly trained on.
- It uses its understanding of language and context to transfer its knowledge to the new task.
- Generalizes without any prior examples
Few-shot learning
- Learn a new task with a few examples When the number of examples used for fine-tuing is only one, it is called one-shot learning;
Multi-shot learning
- Requires more examples than few-shot
- The model learn from previous tasks, plus new examples,
Advantages
- This approach saves time and effort in collecting and labeling a large dataset
- No compromise on accuracy
Building blocks so far
- Data prepration workflow (how data is prepared for computers to understand language)
- Fine-tuning is an effective approach for overcoming the challenges of building LLMs.
- N-shot learning techniques for dealing with the lack of data.
Training Methodology and Techniques
Building blocks to train LLMs
Pre-training : next-word prediction, masked language modeling
Generative pre-training
LLMs are typically trained using a technique called generative pre-training
Providing the model with a dataset of text tokens and training it to predict the tokens within it.
Two types commonly used styles of generative pre-training are next word prediction and masked language modeling.
next word prediction
Supervised learning technique : Model trained on input-output pairs
Similarly, a next word prediction model is used to train a language model to predict the next word in a sentence, given the context of the words before it.
The model learns to generate coherent text by capturing the dependencies between words in the larger context.
Training data : pairs of input and output examples
Masked language modeling
- Hides a selective word
- Trained model predicts the masked word
These techniques are used to learn the contextual representation of words.
Steps : tokenization, word embedding, pre-training, fine-tuning
Introduction to transformers
What is a transformer ?
Transformer architectures emphasizes long-range relationships between words in a sentence to generate accurate and coherent text.
It has 4 essential components : pre-processing, positional encoding ,encoders and decoders.
Inside the transformer
- step 1 Text pre-processing and representation + Positional encoding :
Text pre-processing –> tokenization, stopt word removal, lemmatization
Text representation –> word embedding
Positional encoding –> Information on the position of each word , Understand distant words
the transformer pre-processes input text, converting it to numbers and incorporating position references (转换器预处理输入文本,将其转换为数字并合并位置引用)
- step 2 Encoders :
Attention mechanism : directs attention to specific words and relationships
Neural network : process specific features
the encoders uses this information to encode the sentence, which the decoder then uses to predict subsequent words.
- step 3 Decoders :
Includes attention and neural networks
Generates the output
the predicted word is added to the input, and the process continues until the final output completes the input sentence
Transformers and long-range dependecies
- Initial chanllenge : long-range dependency
- The transoformer’s attention mechanism overcomes this limitaion by focusing on different parts of the input
Process multiple parts simultaneously
Limitation of traditional language models : Sequential - one word at a time
Transformers Process multiple parts of the input text simultaneously, speeding up the process of understanding and generating text.
Attention Mechanisms
- Understand complex structures
- Focus on important words
for example, book reading analogy : clues in a mystery book, focus on relevant content and consentrate on crucial input data
Self-attention and multi-head attention
self-attention : weights the importance of each word in a sentence based on the context to capture long-range dependencies
Multi-head attention : next level of self-attention, splits input into multiple heads with each head focusing on diffenret aspects (多头注意力:下一个层次的自注意力,将输入分成多个头,每个头专注于不同的方面)
Multi-head attention advantages
- “The boy went to the store to buy some groceries, and he found a discount on his favorite cereal”
Attention : “boy”, “store”, “groceries”, and “discount”
Self-attention : “boy” and “he” –> same person; il also identifies the connection between “groceries” and “cereal” as related items within the store
Multi-head attention : multiple channels :
one might focus on character (“boy”), Action (“went to the store”, “found a discount”); things involved (“groceries”, “cereals”)
Advanced fine-tuning
Reinforcement Learning through Human Feedback (RLHF)
Pre-training :
LLM :
- LLMs are pre-trained on large amounts of text data from divers sources, like websites, books, and articles
- using transformer architecture.
- Learns general language patterns, grammars, and facts
Next word prediction
Masked language modeling
Fine-tuning
after pre-training, the model is fine-tuned using N-shot techniques (such as zero, few, and multi-shot) on small labeled datasets to learn specific tasks.
BUt, why RLHF ?
- The concern is that the large general-purpose training data may contain : Noise, errors, and inconsistencies, reducing its accuracy in specific tasks
for example, when a model is trained on data from online discussion forums, il will have a mix of unvalidated opinions and facts. The model treats this training data as the truth, therefore reducing the accuracy. RLHF introduces an external expert to validate the data and avoid these inaccuracies.
Start with the need to fine-tune
- Pre-training : learns underlying language patterns; doesn’t capture context-specific complexities
- Fine-tuning : Quality labeled data improves performances
- Enter RLHF : human feedback !
Simplifying RLHF
- Model output reviewed by human
- update model based on the feedback
Steps :
- Step 1 : Recevies a prompt, and generate multiple responses
- Steps 2 : Human expert checks these responses, ranks the responses based on quality (accuracy, relevance, coherence)
- step 3 time for feedback : learns from expert’s ranking, to align uts responses in future with their preferences
- And it goes on : the model continues to generate responses, receive rankings from the expert, and learn.
Recap
- Pre-training to learn general language knowledge, fine-tuning for specific tasks, RLHF techniques to enhance fine-tuning through human feedback, combination is hghly effective !
Concerns and Considerations
Data concerns and considerations
How LLM are changing the AI landscape, especially in how we use language, and summarized how they are constructed.
- Data volume and compute power
- Data quality
- Labeling
- bias
- Privacy
Data volume and computer power
- LLMs need a lot of data : training one such model can cost millions of dollars worth of computational resources
Data quality
- Quality data is essential
- Accurate data = better learning = improved, response quality = increased trust
Labeled data
- Correct data label : accurate learning, generalized patterns, accurate responses
- Labor-intensive : ex. assigning correct label to each aricle
- Incorrect labels impact model performance
- address errors :identify –> analyze –> iterate
Data bias
Ensuring bias free data is as important as its quality and accuracy for any model including LLMs
- influenced by societal stereotypes
- lack of diversty in training data
- Discrimination and unfair outcomes
- Spot and deal with the biased data : evaluated data imbalances, promote diversity, bias mitigation techniques (more diverse examples)
Data privacy
The data mau contain sensitive or personally identifiable information (PII)
- Compliance with data protection and privacy regulations
- Privacy is a concern : training on data without permission can lead to a breach 未经许可对数据进行训练可能会导致违规
Recap : Where are LLMs heading ?
Model explainability
- How do they arrive at their outputs ?
- Poad-trip planning
- Build trust and transparency
- Identifiy and correct the biases or errors
Efficiency
- Computational efficiency : high-quality output with less compute
- Faster and efficient : model compressions, optimization
- Benefits : better storage, lower energy use
- Accesibility and sustainability : Promotes green AI, Reduces operating costs
Unsupervised bias handling
- Biased data –> discrimination
- Handling bias in an unsupervised manner is an exciting area of research, that explores methods and techniques to detect and migrate biases automatically.
- Unsupervised means that the LLM algprithm of the future would not need explicit human-labeled data; instead, it would autonomously identify and reduce biases by analzing patterns within the training data
- Chanllenge : biases can be subtle and hard for algorithms to detect without human guidance, giving rise to the fear that new biased might get introduced in this process